Recovering a corrupt 6.7 VCentre after a storage outage
I think that there is a law in the UK which dictates that bank holidays can never be nice.
During this years August summer bank holiday (and the coldest day of summer for some years), my lab synology decided to crash. Unfortunately, this synology holds a bunch of VM's including my VCentre VM and Vcentre does not like having it's disk removed from under it.
If you are ever unfortunate enough to have a storage issue where you lose the storage and corrupt VCentre, best practise is to restore VCentre from backup, it does not matter if that backup has been taken by the inbuilt VCentre appliance backup or by a backup tool like Veeam. It is just important to have a backup. In this case though I will admit that I was curious about seeing if VCentre had suffered any issues and looking at the options to repair and recover if possible.
With VCentre down I had to connect direct to the ESXi host that the VCentre VM is hosted on and check the status of VCentre via the console. In this case VCentre was in a strange state where it was running but with lots of SCSI sense errors. I was not able to cleanly shut it down so it had to have a hard reboot. VCentre booted up just fine and at first I thought I might have gotten away with it as everything looked good in from the appliance screen:

That summary page only talks about CPU, RAM and so on. The real detail is under the services and it was here that I could see that VXPA service wasn't running. Starting it provided a nasty error message:
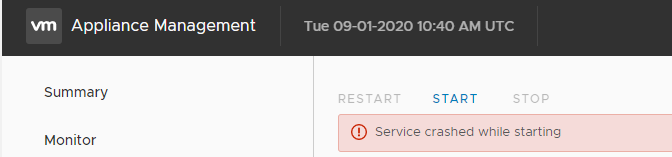
At this point I needed to figure out why VXPA was crashing. The best way to do this was to start the service manually from the shell and see if I got any details. I run VCentre 6.7 and it is a failry simple task to SSH onto the appliance then get into a shell with the 'shell' command.
Running the command service-control --start vmware-vxpd gave me an error saying that the service couldn't be started. The error message was not helpful:
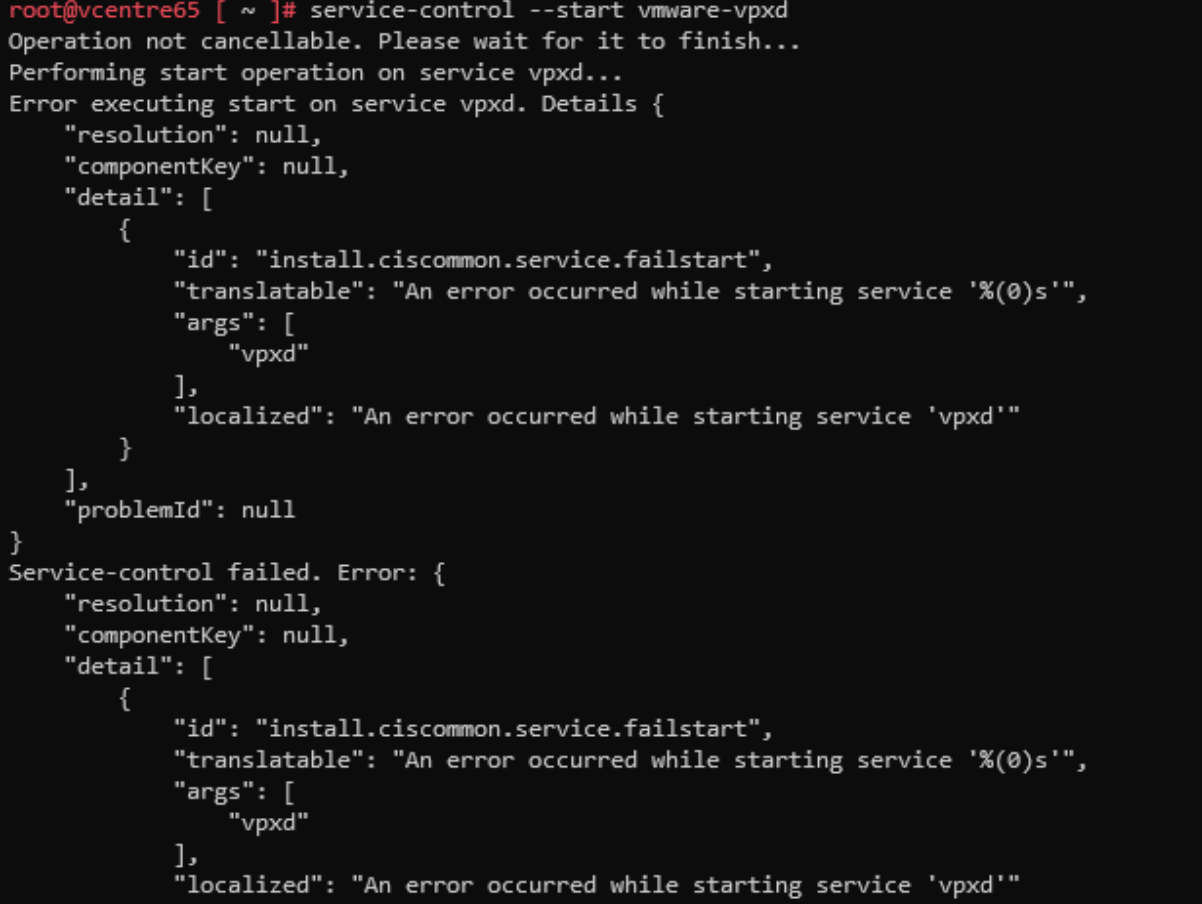
There was one last place I could look to see if I could spot why the vmware-vxpd service was having a bad day and that is in the vxpd log.
Taking a look I saw this:
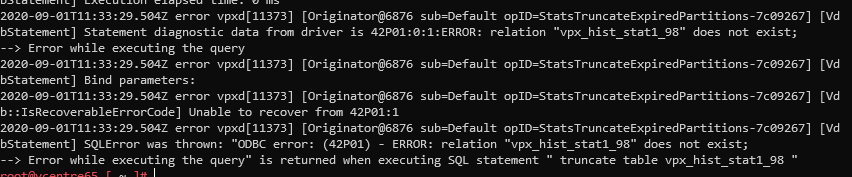
That last line is interesting, it says 'error when executing truncate table vpx_hist_stat1_98'
In SQL, truncate table means to dump all the data from a table, it's basically a delete all while keeping the table structure intact. If the reason that VPXD cannot start because it cannot truncate a table then it should be a simple matter to create table with the correct structure for VXPD to truncate.
In order to to do this, I needed to get into the postgres database. Accessing postgres on VCSA is pretty easy, it can be done with the command:
/opt/vmware/vpostgres/current/bin/psql -d VCDB -U postgres
Listing all the tables can be done with the command
\dt vpx_hist_stat9*
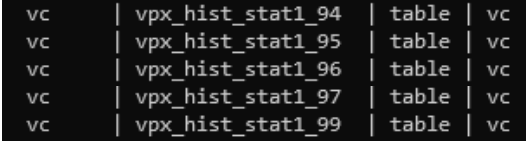
And what do you know? vpx_hist_stat1_98 is missing. I can see plenty of other tables with a similar naming scheme so I'm assuming that vpx_hist_stat1_97 is a previously truncated table that is just kept around for reasons. Now, Postgres, like all SQL implementations allows for an exiting table structure to be copied to a new table so, if I do that I should have an empty vpx_hist_stat1_98 table for the start up script to truncate
of course this is a bank holiday and so things are not allowed to be that easy!
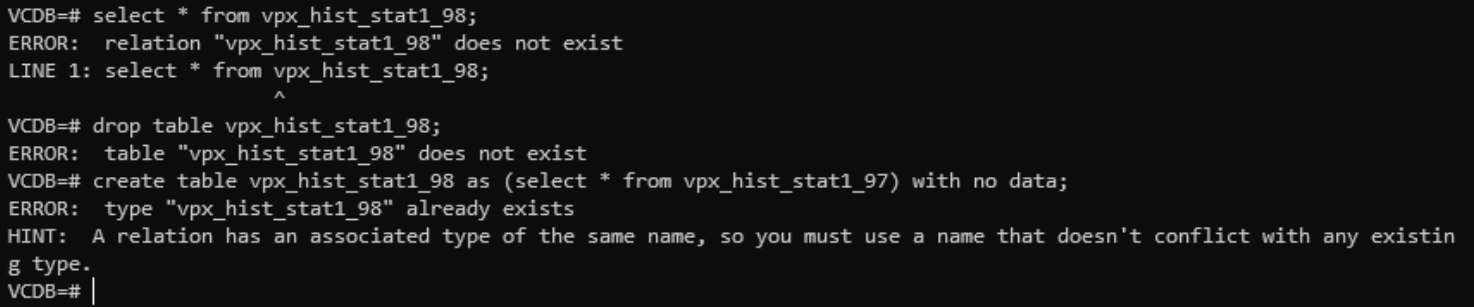
As you can see above, firstly I tried to see the contents of the vpx_hist_stat1_98 table and got an error because it didn't exist and then I tried to clone the table from a previous one but that wasn't allowed because it already exists and finally I tried to drop the table but that also didn't work.
In essence, Postgres is telling me that the table both exists and doesn't exist depending on what I'm trying to do to it.
So, what to do?
In all SQL implementations I've come across there is a table of tables - this table pretty much tells the database engine what tables exist in the system. Postgres is no different and so, what I need to do is tell the postgres database of databases that vpx_hist_stats1_98 doesn't exist. This means updating the table of tables with the command:
delete from pg_type where typname~'vpx_hist_stat1_98';
This is a bit of a brute force delete and not exactly advisable as it is really getting down into the depths of postgres but I was curious if this would work so I gave it a go.
Now that postgres has been told that the offending table doesn't exist it should be possible to clone another database and this time, success!

The last command to run is the one to change the owner from postgress to vc. I suspect that if I tried to start up vmware-vxpd with the owner set as postgres it would fail with permissions errors.
Changing the owner of a table in postgres is done with the command:
alter table vpx_hist_stat1_98 owner to vc;
Now that the vmware-vxpd servvice has an empty table that it can happily truncate so it should start and indeed it did, after a few minutes VCentre was fully up and running for me to use.
I have run with this version of vcentre for a week now with no issues. I suspect that it is all okay although I do need to add the comment that this is not something I recommend unless there is literally no other option for getting a broken vcentre up and running. Of course, the issue may well be with a different table than the one I had to fix and I was very lucky that the one I had trouble with was one that VMWare wanted postgres to truncate anyway so there is literally no concern about data loss.
The last thing I will add is that if you don't already - backup your VCentre and if you are not sure how to do that, check back here in a few days when I will show you how to do it using the in-built VMWare appliance tools.
Subscribe to Ramblings of a Sysadmin
Get the latest posts delivered right to your inbox