CDN's - the new internet based single point of failure?
On 8th June, the CDN provider Fastly had an outage that they associated with a 'configuration issue'. What that issue was, Fastly have so far refused to say although they have alluded to it being a customers configuration and not something they directly did. They have also admitted that it is something that they should have forecast.
Outages are going to happen. Anyone who works in IT knows this. Things break and I will admit that my banner here is a little click-baity as the reason companies and even individuals use providers like fastly is because they don't have to maintain the infrastructure and an outage like we saw on 8th June is a very rare thing.
Despite everything I have said, I do wonder just how many companies that have full DR and business continuity plans actually take into account an outage of an upstream provider like Fastly. During the outage it was pretty obvious just how many sites were either fully behind fastly or had some elements reliant on Fastly.
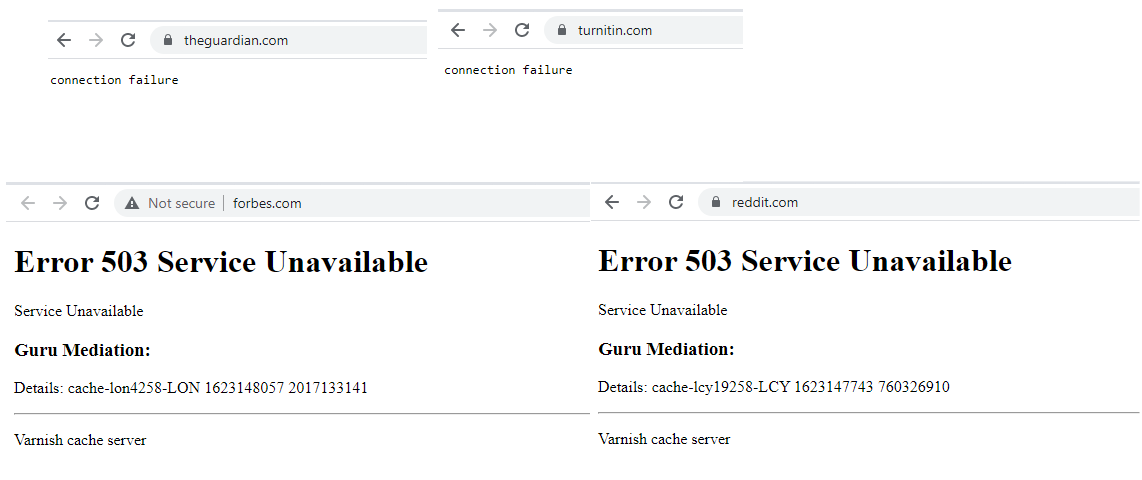
As site note, it is interesting to see that Forbes shows up as not secure. This makes me wonder if they are using SSL offload with faslty and if the data from fastly down to forbes is actually unencrypted.
Above are screenshots of several websites that had issues during the outage. There's a lot more of course but I didn't want to cover this whole blog with similar screenshots! It's pretty clear that some big websites like Reddit and forbes are behind fastly and this makes sense.
The more hits a site gets the more the need for a CDN to help manage the load on the servers themselves and it is far easier to use a service like Fastly rather than put servers all over the world and deal with the inevitable sync issues.
While issues like the one that fastly suffered are rare, I do think that as IT pros we do need to consider what happens should upstream providers like ISP's and CDN's have a major failure, attack or even what happens if they go out of business. All of these are potentially real scenarios. All of these should have some level of DR and BCP planning. It's time for a DR and BCP plans to evolve to take into account this brave new world of upstream SaaS and PaaS providers.
Focusing on this outage, I do worry a little as Fastly are being somewhat tight lipped as to the outage:
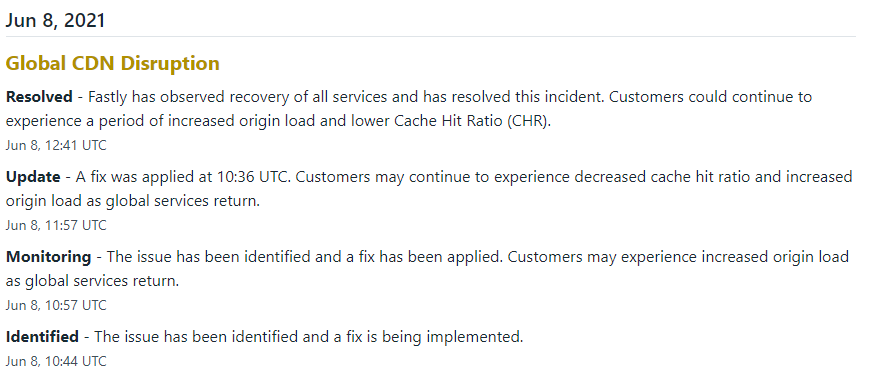
I always get suspicious when a company doesn't go into details as to the issue. I do think companies like fastly have a duty to disclose more technical information simply because they have so much internet traffic going through them but of course, Fastly are a private company and as such, don't have to say a single thing about this outage. Until and unless there are data sharing requirements around such outages I do think that companies need to add upstream providers into both their risk portfolios and their DR and BCP practicies.
UPDATE
Well, It seems that Akamai felt the need to copy Fastly as just six weeks after Fastly took a nose dive so did Akami (https://www.bleepingcomputer.com/news/security/akamai-dns-global-outage-takes-down-major-websites-online-services/)
Akami have released a statement saying that the problem was DNS:
At 15:46 UTC today, a software configuration update triggered a bug in the DNS system, the system that directs browsers to websites. This caused a disruption impacting availability of some customer websites
Once again, this highlights the fragility of the internet when you put everything behind a single companies load balancers.
Subscribe to Ramblings of a Sysadmin
Get the latest posts delivered right to your inbox